Pythonでスクレイピングやってみた

スクレイピングとは
- webサイトからデータを抽出する技術
留意事項
- 規約違反、著作権違反になっていないか確認する
- サーバに負荷をかけないようにする
- HTML構造が変わるとデータ収集ができなくなる
- 頻繁にアクセスしていると不正アクセスとして拒絶されるケースもあり
実際にスクレイピングやってみた
使用技術,ライブラリ
- python3
- BeautifulSoup:(pythonライブラリ)
https://pypi.org/project/beautifulsoup4/
- requests:(pythonライブラリ)
https://pypi.org/project/requests/
流れ
1.WEBサイトからスクレイピング
2.pythonで処理、ターミナルに取得データ出力
対象WEBサイト
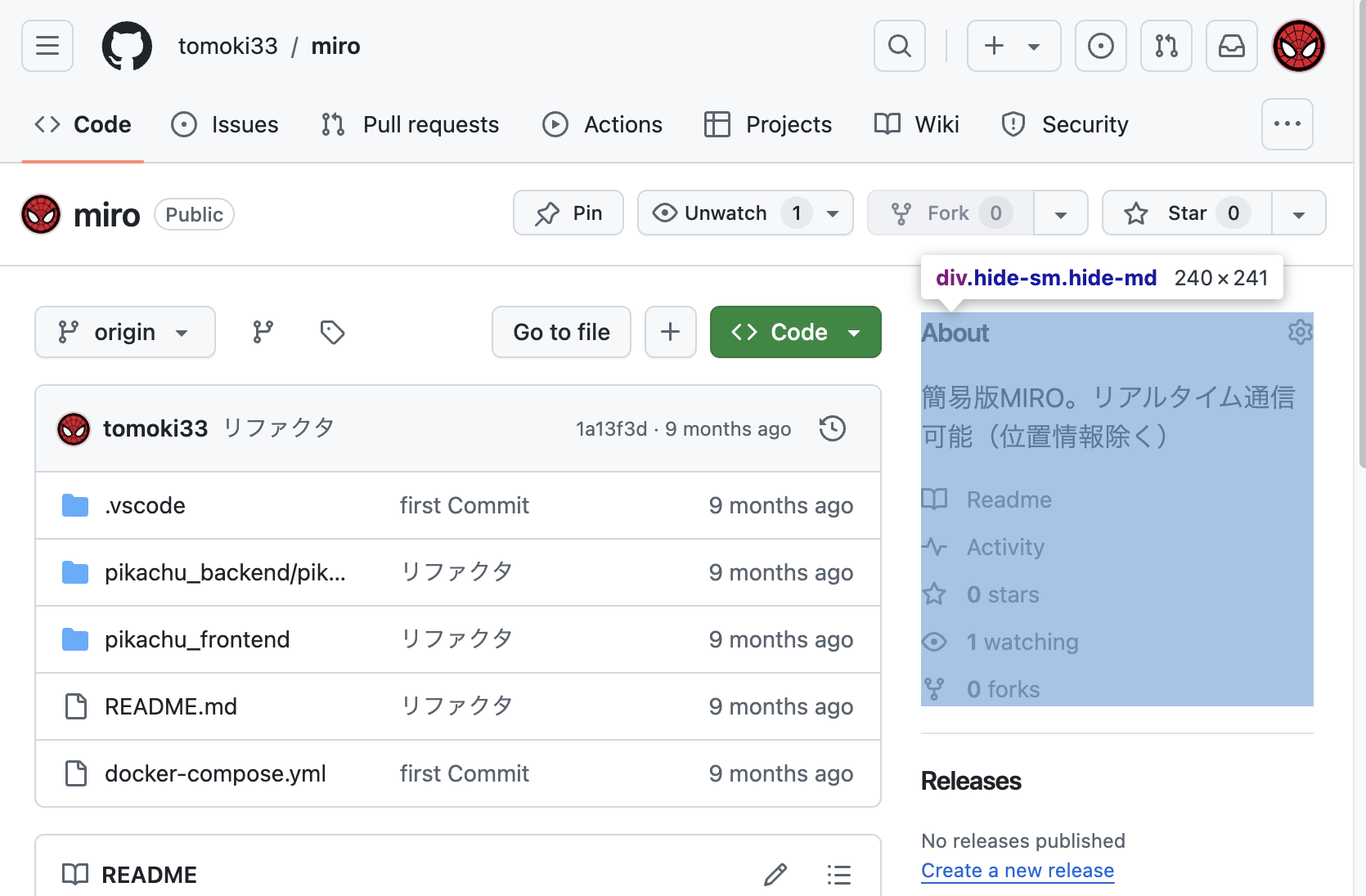
上記の青枠部分がスクレイピング対象
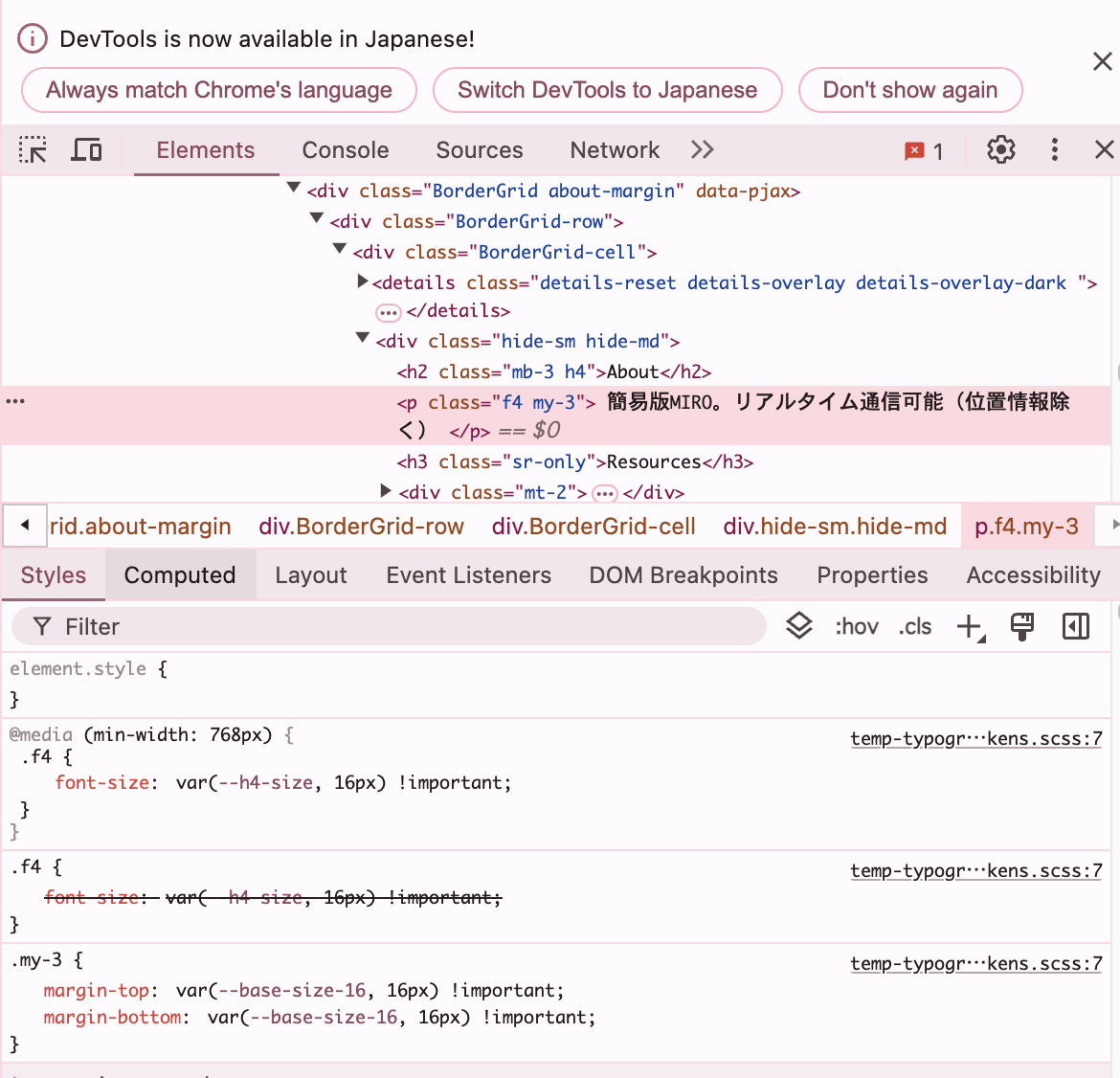
該当HTML箇所(class = hide-sm hide-md)
コード
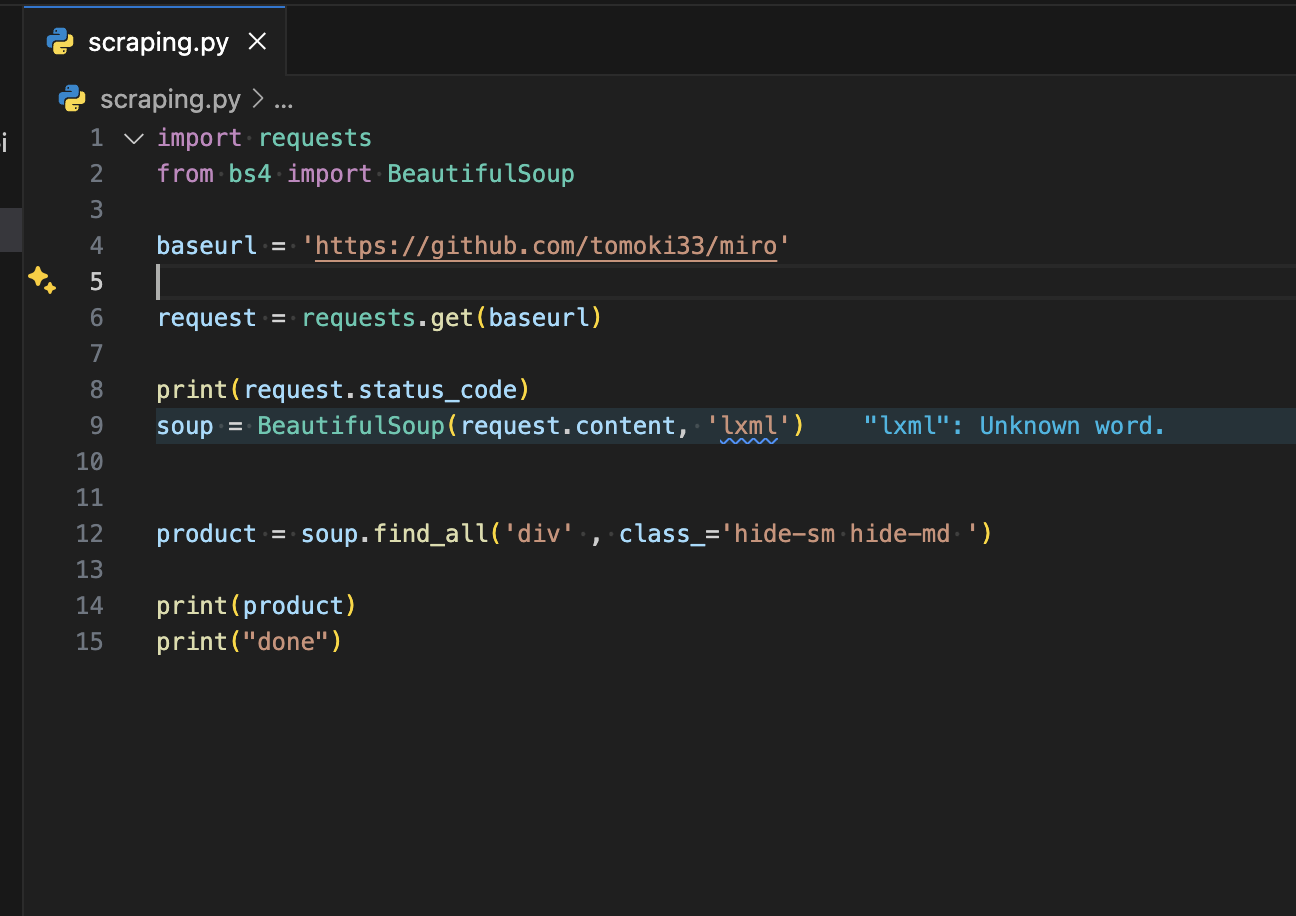
下記出力結果
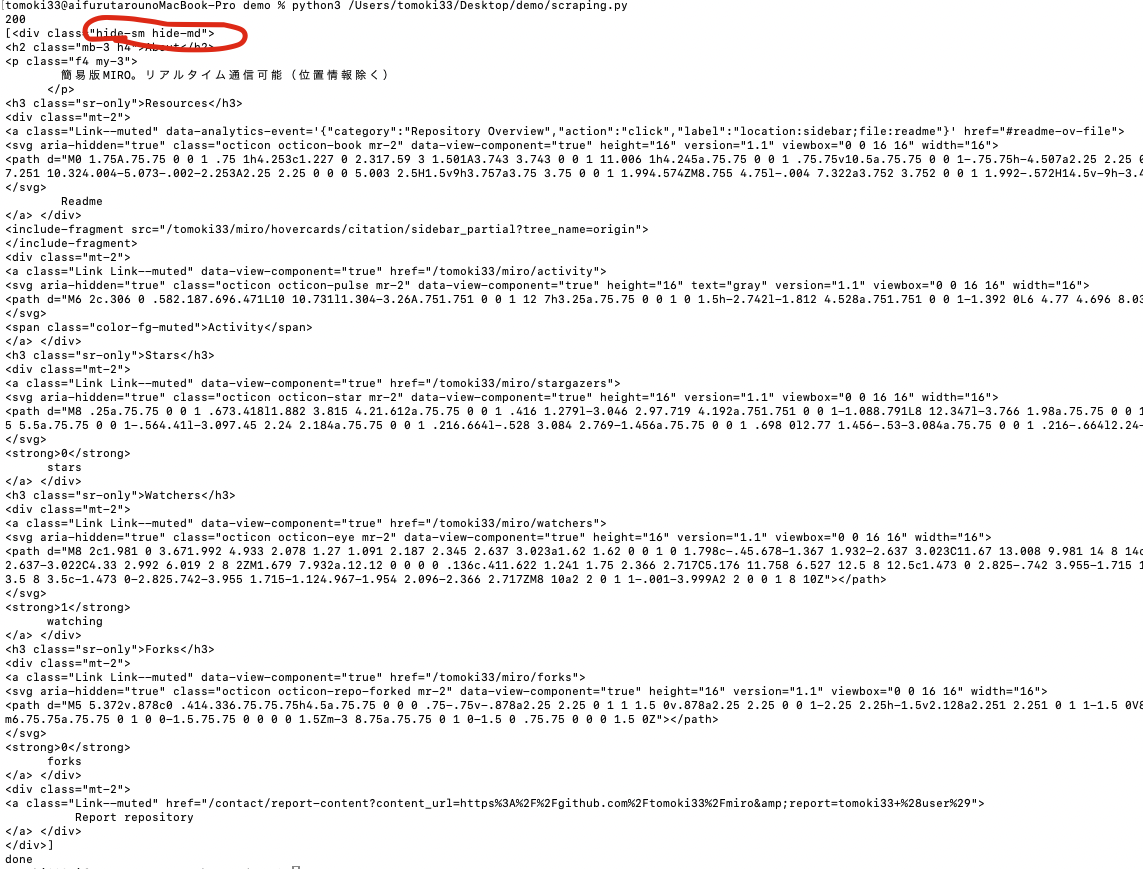
上記サイト上で確認したHTMLを取得。
少しわかりにくいので、文字だけ抽出
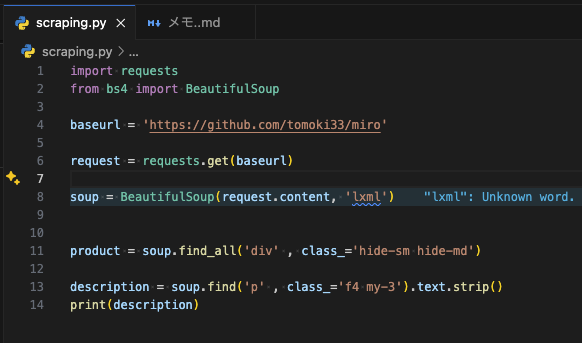
結果。。

文字だけ出力を完了
まとめ
ライブラリがあるのでかなり簡単に実装可能。
スクレイピング禁止サイト等、使い方には気をつけて使用していきたい。

